Inglés
Inglés  Chino
Chino  Alemán
Alemán  Coreano
Coreano  Japonés
Japonés  Farsi
Farsi  Portuguese
Portuguese  Russian
Russian  Español
Español 
2--target detection
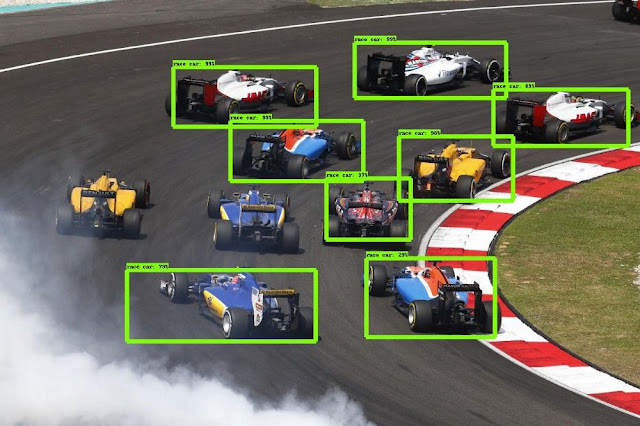
The task of defining a target in an image typically involves the bounding box of a single target and the output of the tag. This differs from the classification/positioning task in that it applies classification and positioning to many goals, not just a dominant goal. You only have 2 types of target categories, the target bounding box and the non-target bounding box. For example, in car detection, you must use its bounding box to detect all cars in a given image.
If we use sliding window technology in a way that classifies and locates images, we need to apply CNN to many different locations of the image. Because CNN classifies each location as a target or background, we need to apply many locations and different scales in CNN, which is computationally expensive!

To deal with this situation, neural network researchers have proposed using regions instead, where we find "blobby" image regions that may contain targets. This area is relatively fast to run. The first compelling model is R-CNN (region-based convolutional neural network). In R-CNN, we first scan the input image using an algorithm called selective search to find possible targets, generating about 2,000 candidate regions. Then we run CNN on a per-regional box basis. Finally, we take the output of each CNN and input it to the SVM to classify the regions and use linear regression to tighten the bounding box of the target.
Basically, we turned target detection into an image classification problem. However, there are some problems - slow training, a lot of disk space, and slow reasoning.
The direct descendant of R-CNN is the fast R-CNN, which improves the detection speed by 2 enhancements: 1) performs feature extraction before the candidate area, so only runs one CNN on the entire image, and 2) replaces with softmax layer SVM, thus extending the prediction of neural networks, rather than creating a new model.
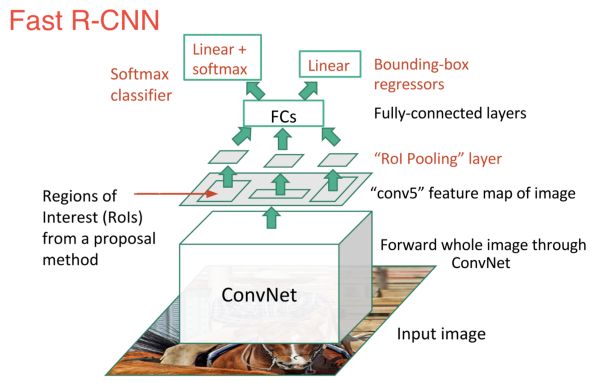
Fast R-CNN performs better in terms of speed because it trains only one CNN for the entire image. However, the selective search algorithm still takes a lot of time to generate candidate regions.
Therefore, a faster R-CNN was discovered, which is now a canonical model for target detection based on deep learning. The region from the feature is predicted by inserting a region generation network (RPN), which replaces the slow selective search algorithm with a fast neural network. The RPN is used to determine "where" to reduce the computational requirements of the entire inference process. The RPN scans each location quickly and efficiently to assess whether further processing is required in a given area. It does this by outputting k bounding box regions, each with 2 scores, indicating the probability of the target at each location.

Once we have our candidate areas, we will provide them directly to the content that is basically a fast R-CNN. We added a pooling layer, some fully connected layers, and finally a softmax classification layer and bounding box regenerator.
All in all, the faster R-CNN achieves better speed and higher accuracy. It's worth noting that although future models do a lot of work to improve detection speed, few models can surpass faster R-CNNs with higher advantages. In other words, a faster R-CNN may not be the easiest or fastest way to detect a target, but it is still one of the best performing methods.
The main target detection trend in recent years has turned to faster, more efficient detection systems. This is seen in methods such as You Only Look Once (YOLO), Single Shot MultiBox Detector (SSD) and Region-based Complete Convolutional Network (R-FCN) as a way to share calculations across the entire image. Therefore, these methods distinguish themselves from the expensive subnets associated with the three R-CNN technologies. The main reason behind these trends is to avoid having separate algorithms focus on their sub-problems in isolation, as this usually increases training time and reduces network accuracy.
to be continued
Follow Me
Follow Me